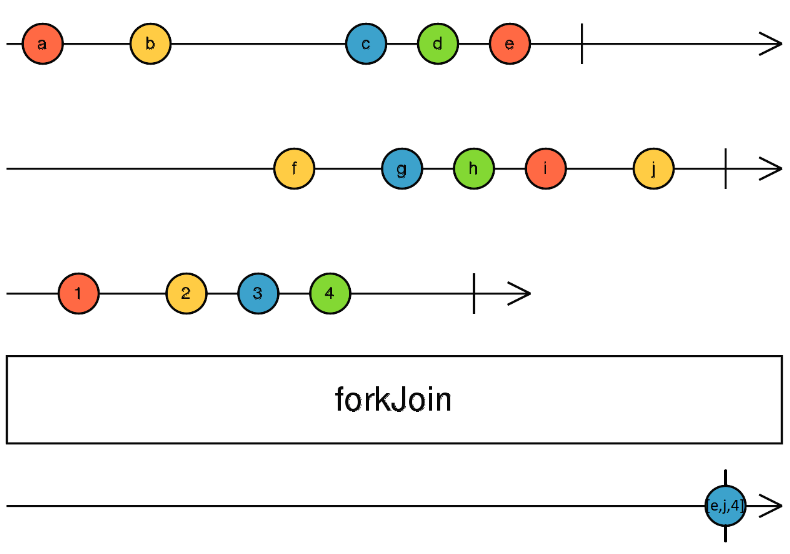
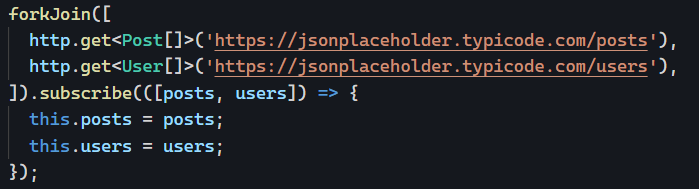
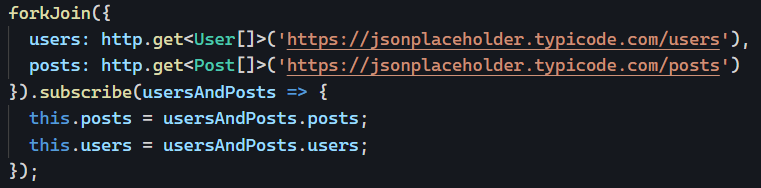
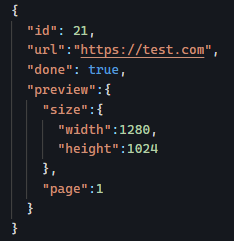
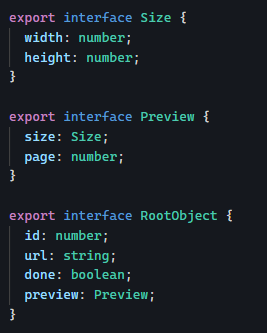
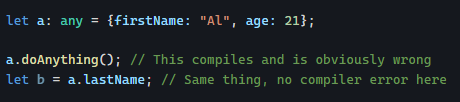
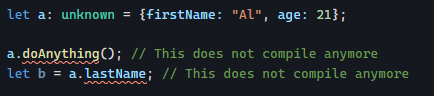
Yesterday, we saw how using directives instead of components can increase code reusability by not tying our code logic to a specific HTML template.
Now, if we want to write some code once and for all and make it work for all HTML elements in our app that match some specific conditions, we have another underused tool at our disposal: CSS selectors.
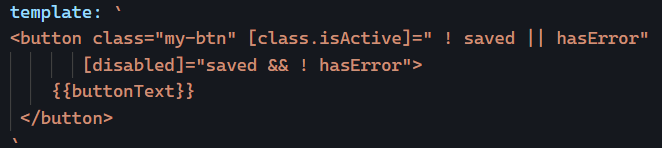
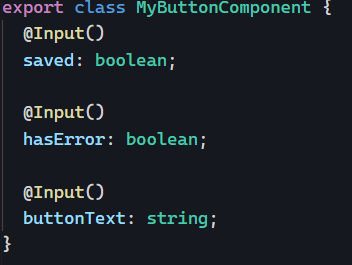
For instance, let’s say we want the isActive directive from our previous example to be applied to all buttons in our application. Of course, we could manually look for all buttons and add the isActive attribute to them, but that would be tedious and error-prone.
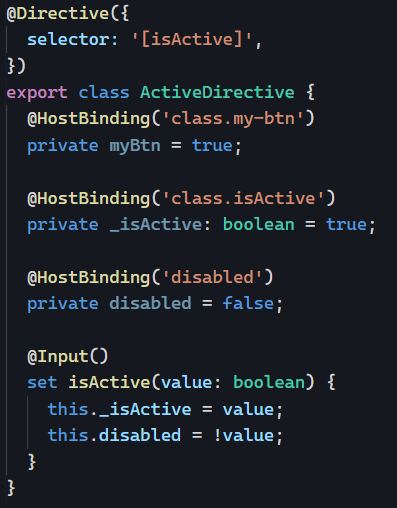
Or we could be more imaginative and change the selector of that directive so that it applies to all buttons and any other elements that have an isActive attribute:
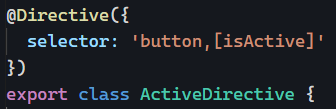
With that implementation, all current (and future) buttons will have that directive applied to them. But what if we want to make any exceptions and disable the directive on some buttons? That’s how we could do it:

Then all we would need is to add the disableIsActive attribute to those buttons that don’t want the isActive directive:
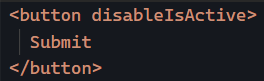
My point here is that there are some creative use cases for CSS selectors, and those selectors are the same as those used for CSS styling, meaning that we can rely on classes, attributes, element names, or any combination of the above!
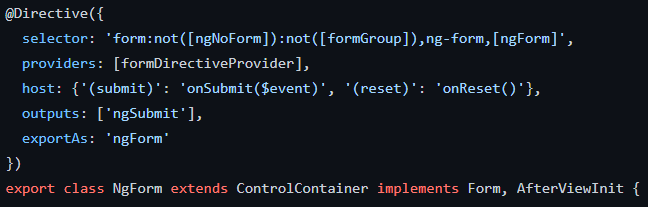
The Angular framework does precisely that in quite a few places. If you’ve ever wondered how forms get auto-magically handled by Angular, now you know the answer. The ngForm directive has a complex selector that would apply to all form elements by default: