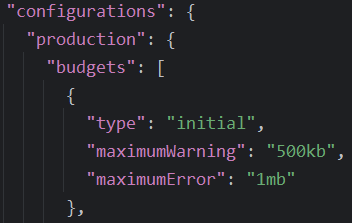
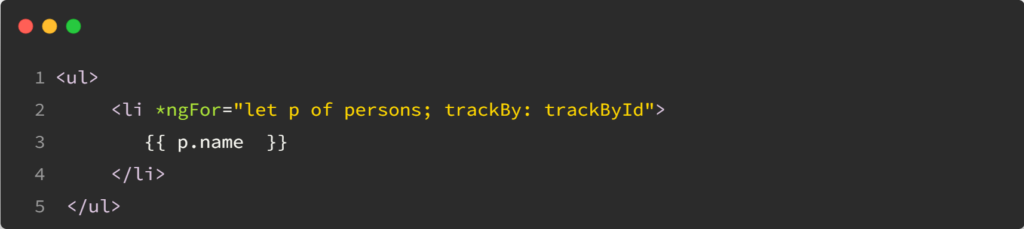
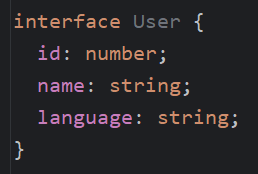
Typescript has a lot to offer when it comes down to… types. Which makes perfect sense, right? Let’s take a few examples based on the following interface:
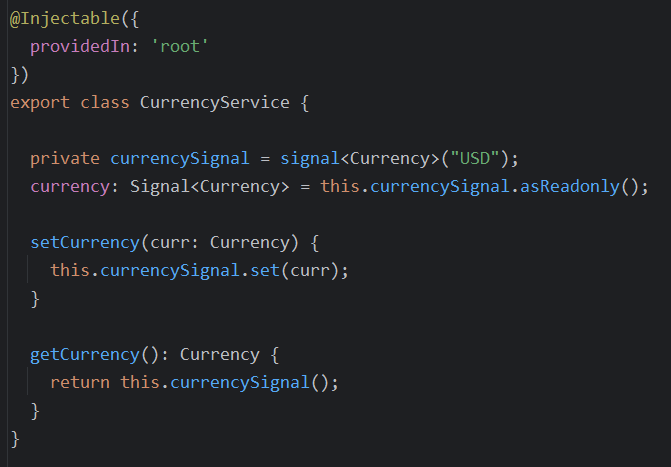
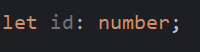
The following variable is meant to store the id of a User in our application. The type of that id is a number, so this declaration is accurate:
But could be a lot more precise if we used the following syntax instead:

Now we are expressing that id is of the same type as User id (which is still a number), and we make it explicit that we’re using this variable to store a User id, not just any number. We are using an indexed type.
We can use a similar approach for our language. Instead of being any string, we can narrow that type using union types:
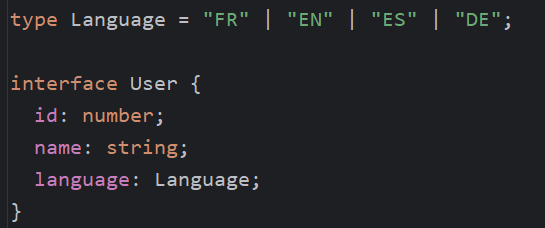
A user’s language can only be one of the four listed values. This makes our code safer (a typo would be caught by our compiler and IDE instantly) and doesn’t impact performance (union types do not get compiled into anything).