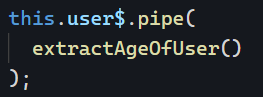
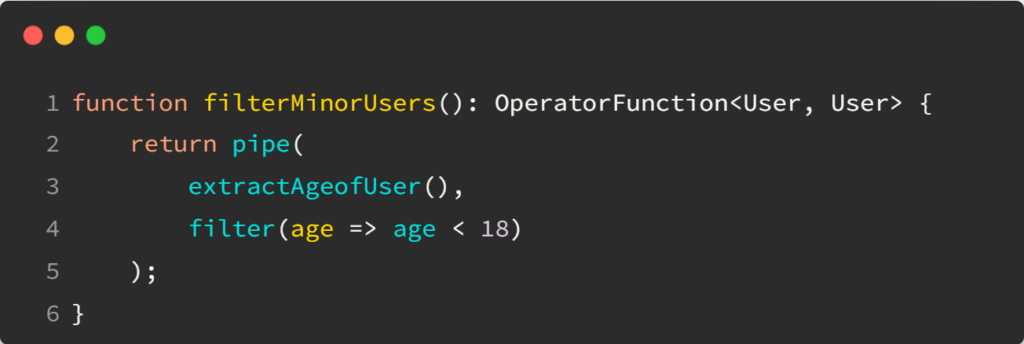
So far, we have covered several RxJs operators and information about Subjects, but what about Observables themselves?
There are a few utility functions that create Observables out of existing data. Such Observables immediately return the data and complete upon subscription.
Here is an example of such an Observable created with the of() function:
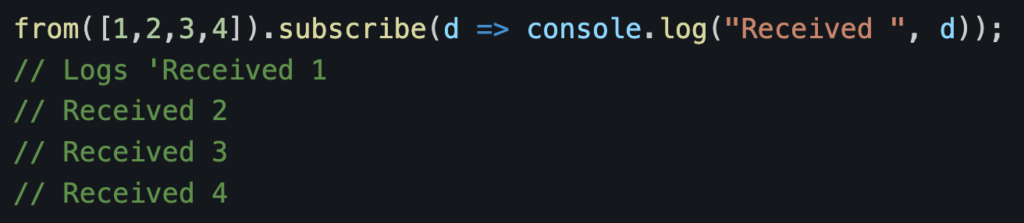
And an example created with the from() function:
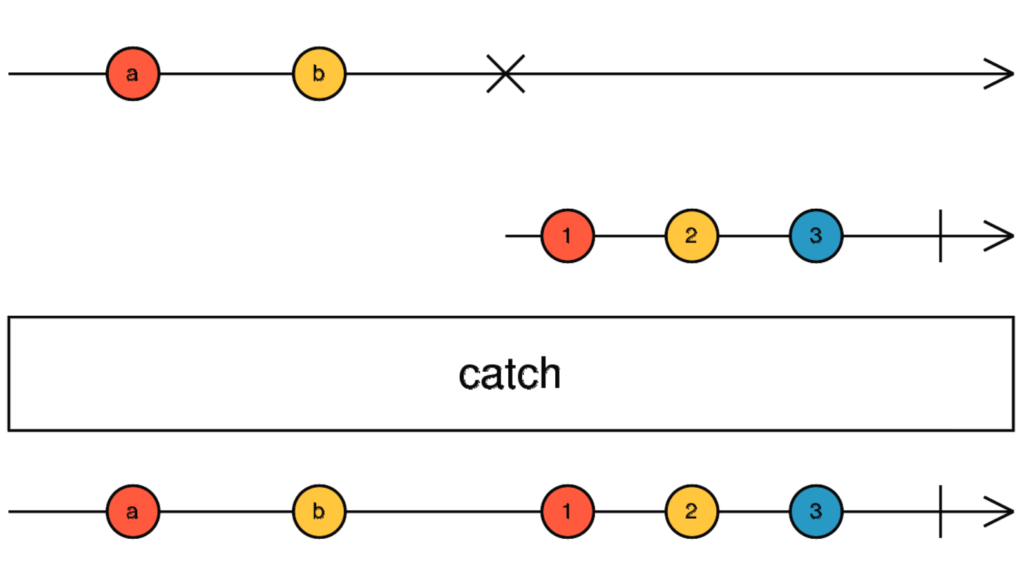
The difference between of() and from() is that of() emits all the data right away in a single emission, whereas from() uses an array of items and emits them one by one with no delay between emissions.
In other words:
What’s the point of an Observable that just returns data instantly and does nothing asynchronous? First is testing. Being able to return to an Observable with hard-coded data is perfect for unit testing purposes as we can quickly validate different scenarios without using the actual HttpClient, for instance.
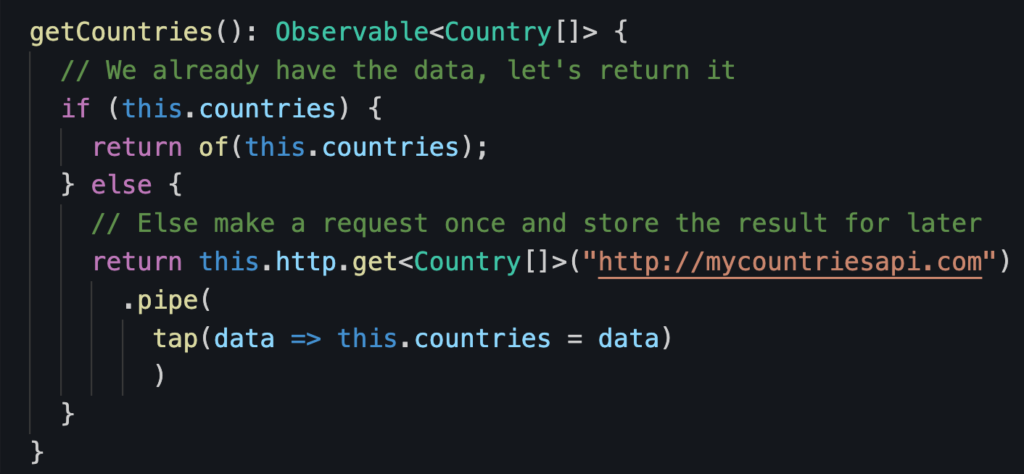
Second is caching data and returning it as an Observable (which can be done even more easily with a BehaviorSubject or ReplaySubject). For instance, say we have a service that retrieves a list of all countries in the world from a server. We know that that list doesn’t change every day, so we want to cache it so that if another component requests that data, instead of making another HTTP request, we return an Observable of that data:
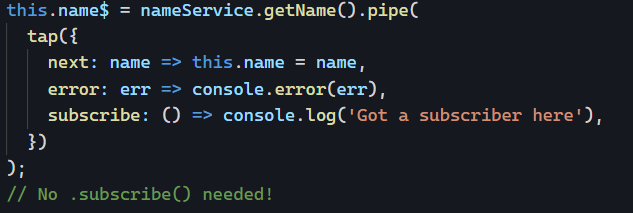
Note the use of the tap operator to spy on the Observable, catch the data, and store it in our “cache” variable.
That way, the API is consistent and components always subscribe to an Observable, not knowing if the data comes from a server or a local cache.