The lifecycle of an Angular application is something that many aspiring Angular developers struggle with. People often ask me questions such as:
- How long does this component/service/directive stay in memory?
- How do I save the data before I navigate to the next page/view/component?
- What happens if I open that same app in another browser tab?
Here is how to think about it:
- When we open an app in a browser tab, we’re booting an Angular application in a self-contained memory space, similar to a virtual machine.
- Closing that tab is equivalent to killing the application, freeing any memory associated with it, just like when you close a desktop app in your machine’s operating system.
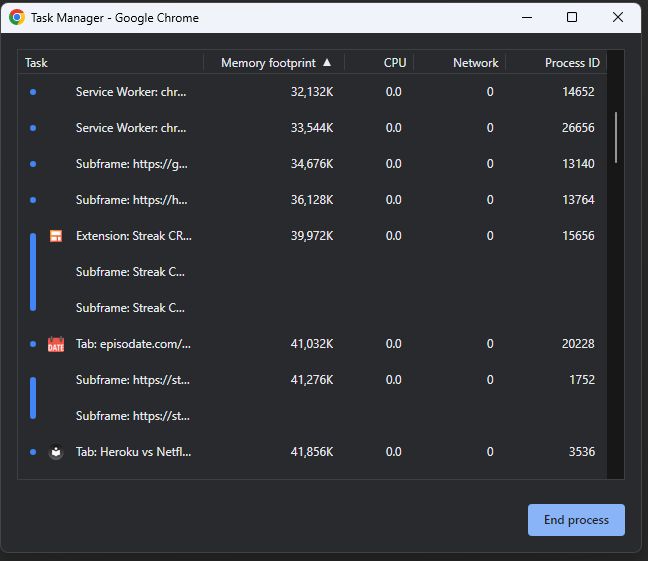
In Google Chrome, there’s even a task manager where you can see the memory footprint and CPU usage of your tabs and browser extensions – they’re just like independent desktop apps:
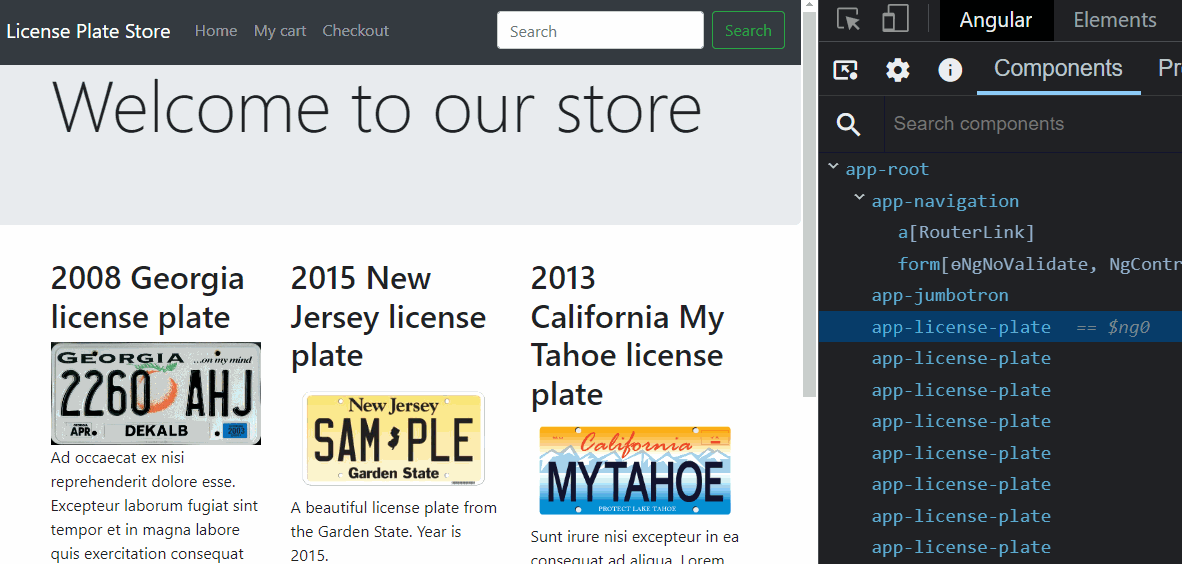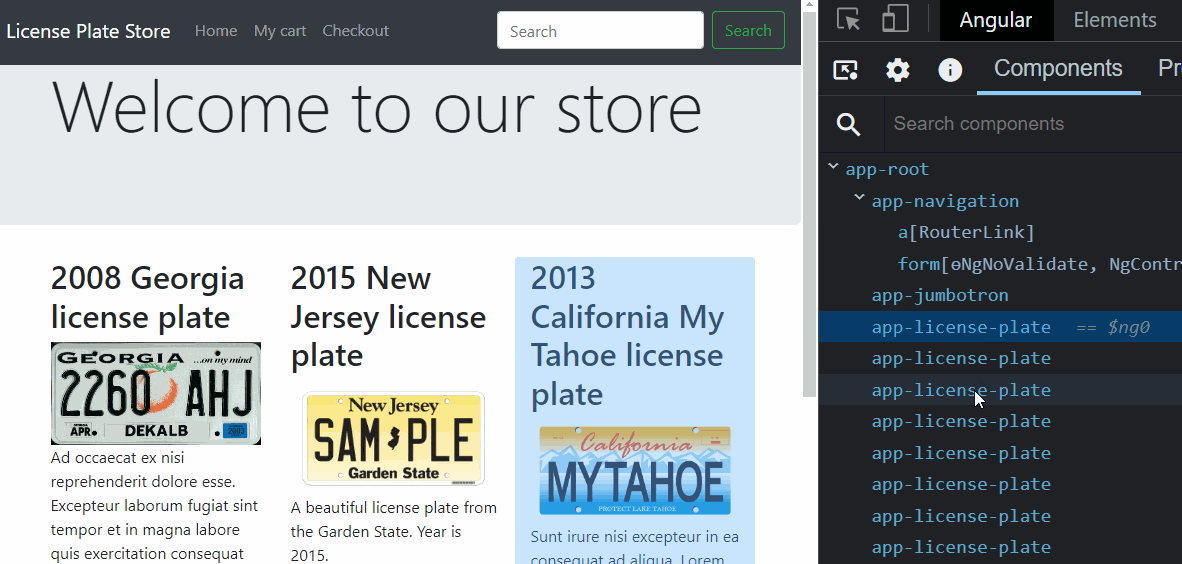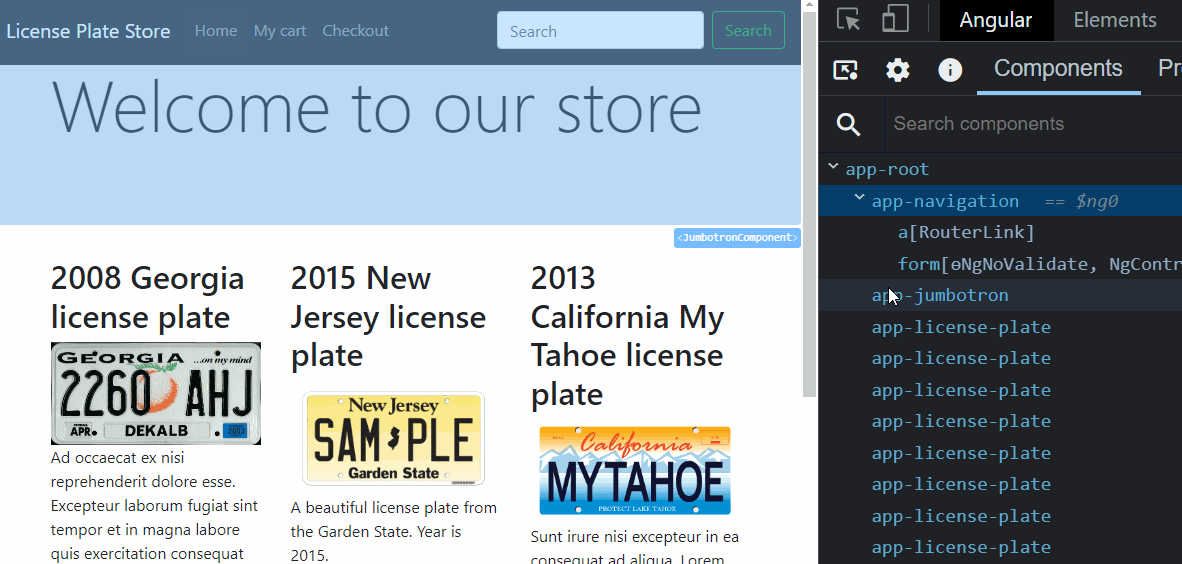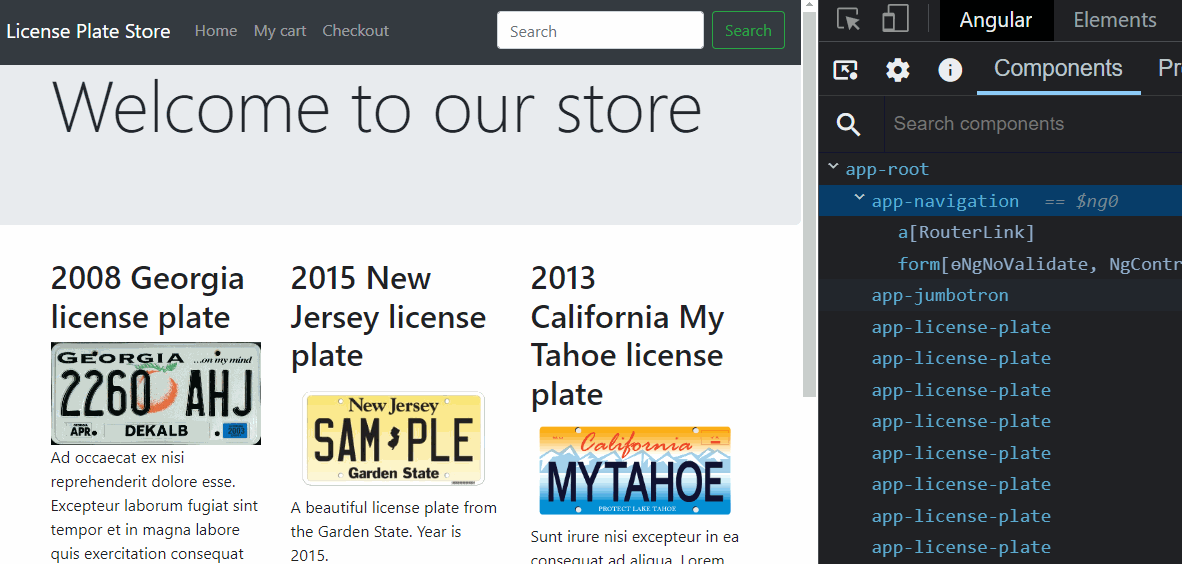
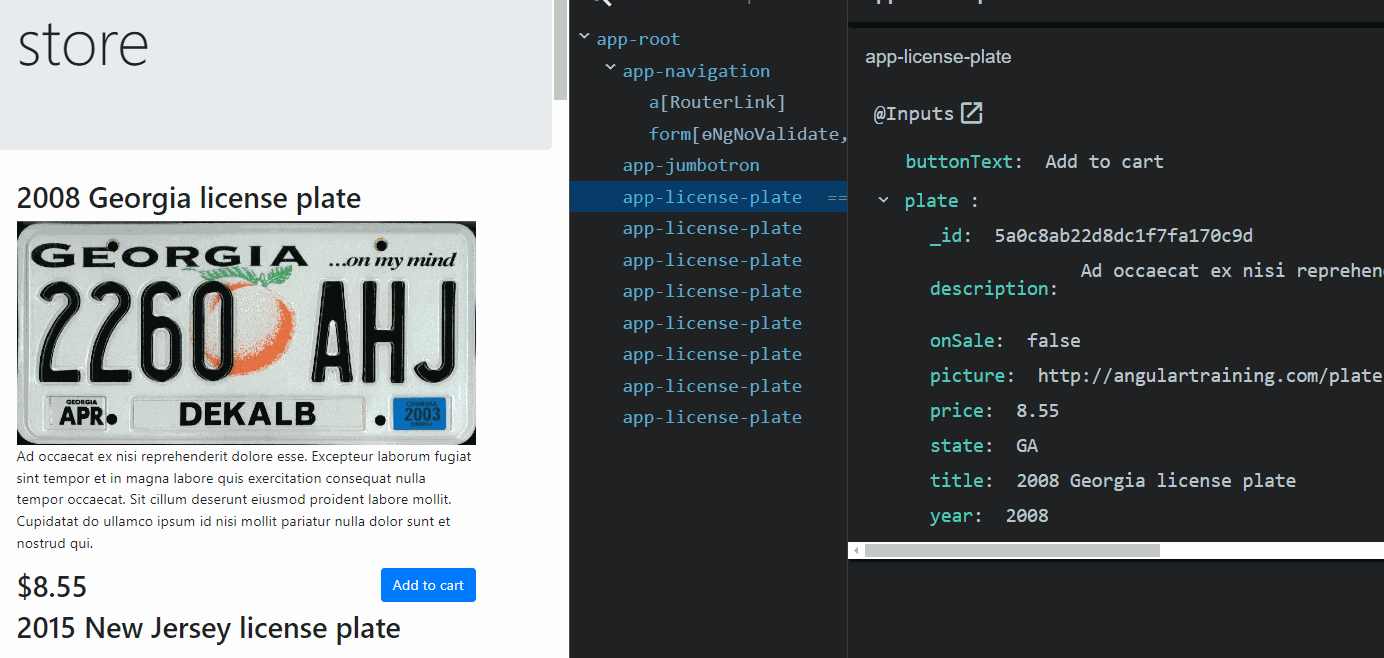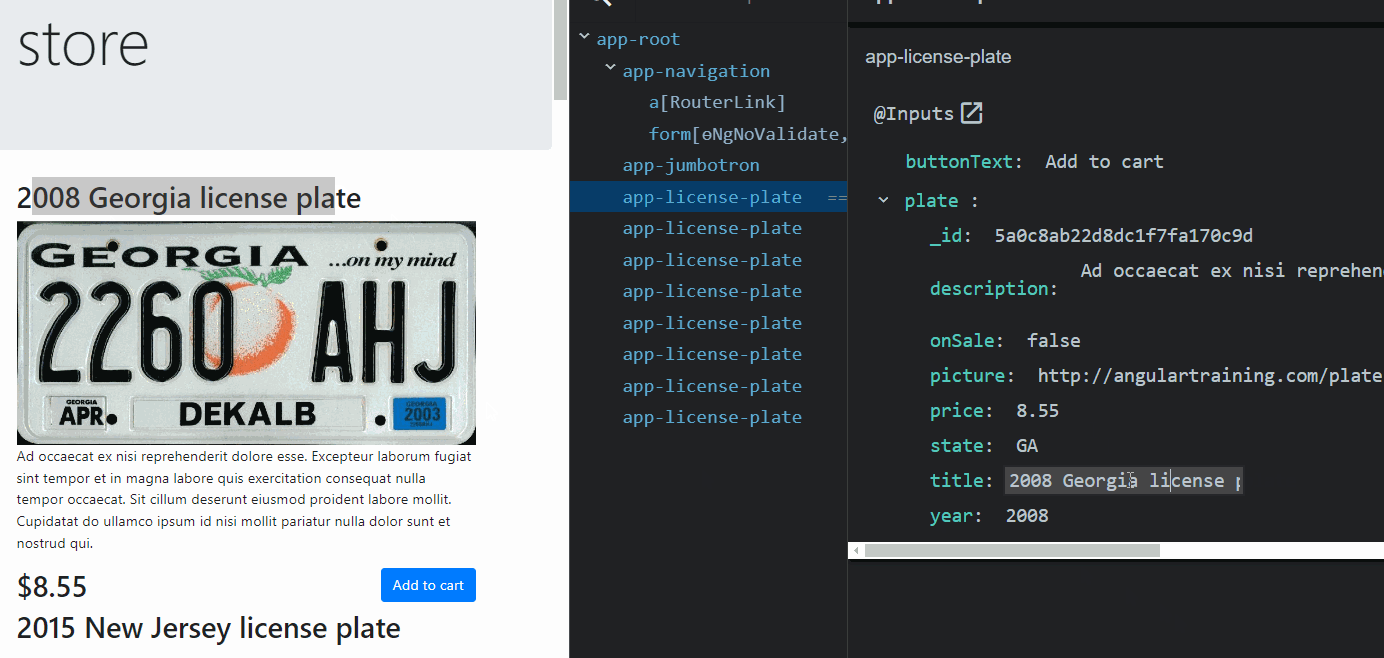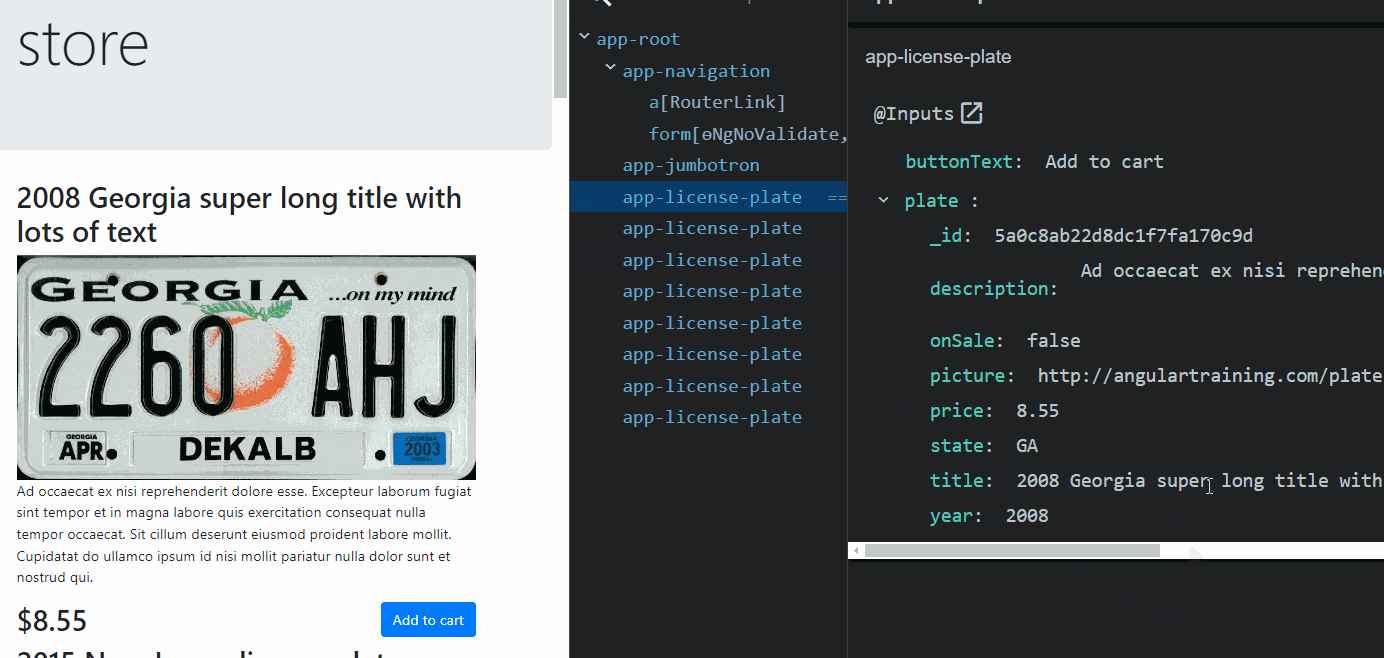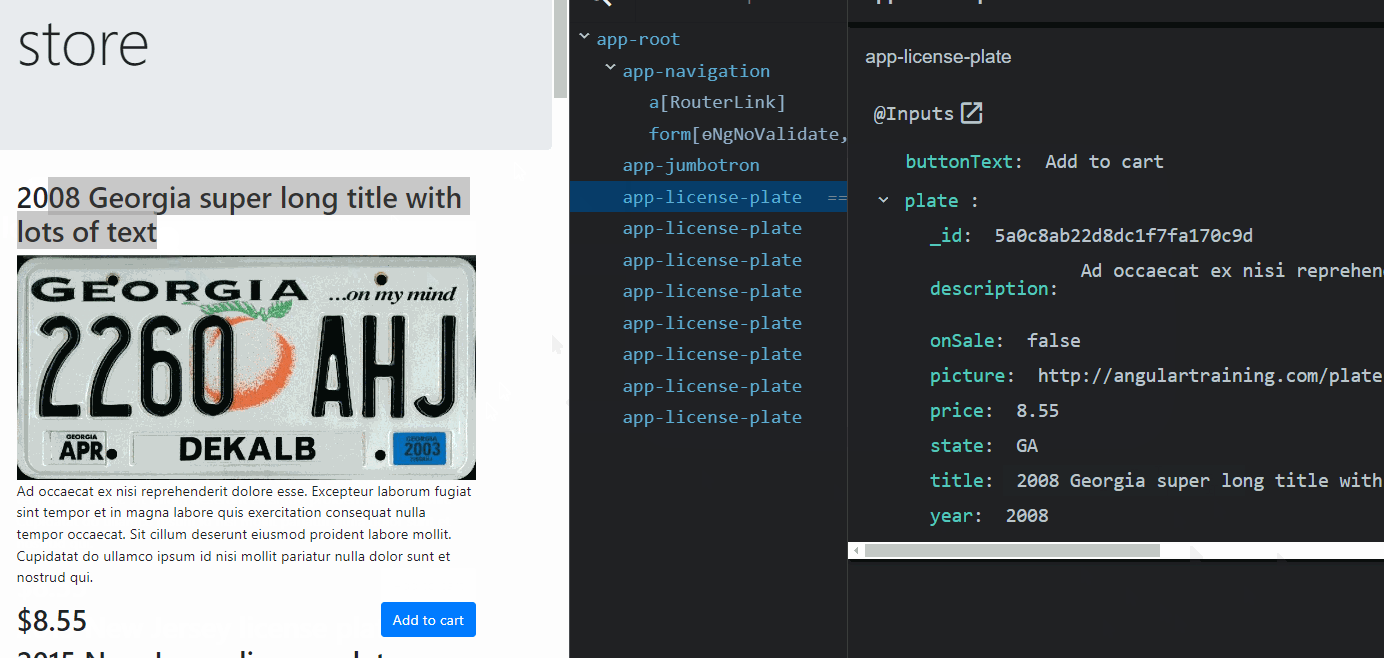
From an Angular perspective, a component gets loaded in memory whenever displayed on the screen. That’s when its class is instantiated.
Suppose the component gets removed from the screen (by navigating to a different component or removing it with a ngIf directive, for instance). In that case, the component is destroyed, and all of its memory state is gone. The same goes for directives and pipes: They get created when used by a component template and destroyed when that component gets destroyed.
Services are different, though. A service is created by Angular when a component needs it for the first time. Then, that instance remains unique and shared between all components that inject such service. A service doesn’t get destroyed: It remains in memory as long as your app is open and you don’t close your browser or tab.
This answers our three initial questions:
- How long does this component/service/directive stay in memory?
Components stay as long as they’re in the DOM. Services stay as long as the app is open. - How do I save the data before I navigate to the next page/view/component?
Not if you save it in a service - What happens if I open that same app in another browser tab?
You create another separate instance of everything: Components, services, etc. Both instances are independent and do not share any data or memory space.